I recently attended the Third Conference on Machine Learning and Systems (MLSys) in Austin, TX. The proceedings are here. I had a great time, learned a lot, and met a lot of interesting people.
The conference was March 2-4, 2020, and tension over the coronavirus was definitely on the upswing. (In fact, the conference was just seven or so weeks ago, but it now seems like an eternity since I last traveled out of Atlanta because of the quarantine.) A large number of people cancelled and many presentations were delivered over Zoom, including one from China. I almost cancelled my own trip. The first cases in Texas popped up while I was there (in San Antonio). Not a lot of hand-shaking, as you might imagine.
The conference itself was great. This meeting brings together both ML and Systems researchers, and a paper must bridge those two fields and pass peer review by people on both sides to be accepted. It was also great to see the emphasis on artifact publication and evaluation (code, datasets, hardware, etc) to support reproducible research.
The attendance was evenly split between about four hundred academic and industry researchers, and the industry representation seemed to be mostly comprised of FAANG-style companies with ML research arms.
MLSys talks
I found a lot of the content interesting and relevant to my work as an industry ML practitioner. At the same time, there were also some academic talks where I honestly had no idea what the speaker was talking about. But you can’t bring together multiple related fields and keep things interesting for everybody, for an entire conference.
My favorite talk of the conference was the first day keynote by Christopher Ré (Stanford University): Theory & Systems for Weak Supervision (YouTube, slides). His talk started by discussing the idea of Software 2.0 (see this blog post or this one, 1.0 is explicitly programmed vs. 2.0 which is abstract and “learned”). The primary idea he was pushing was that while it’s great that we have sophisticated and easy-to-deploy models being published every other week (“new-model-itis”) along with continually improving hardware, the real limiting factors in most ML systems are the quality and quantity of training data. The proposed solution is to replace manually labeled training data (slow, expensive, static) with programmatically labeled training data (fast, cheap, dynamic) via weak supervision. His group has a blog post called An Overview of Weak Supervision that provides a nice introduction. For example, instead of spending months of mechanical turk time tagging records, a few subject matter experts can develop labeling functions in a short amount of time that are noisy but nearly as good in aggregate. This means each particular label might not be as good as if human-labeled, but you now have a million labeled records instead of the 10k or 100k you were going to spend several weeks developing. Other approaches include pattern matching, distant supervision, automated augmentation (see this series of blog posts), topic models, third-party models, or crowdworker labels. Ré’s research group develops and maintains a Python package for programatically building and managing training data called Snorkel. In the Snorkel paradigm, the user will write labeling functions that generate noisy and perhaps conflicting labels, then Snorkel will model and combine these noisy labels into probabilities. The actual model is then trained using these probabilitistic labels and can discover and exploit structure in the training data that goes significantly beyond the heuristics expressed in the labeling functions. The lift generated in the presented examples was wild. Also really enjoyed his discussion of hidden stratification.
Alongside the idea of improving training data, Wu et al. gave a great talk on Attention-based Learning for Missing Data Imputation in HoloClean. The HoloClean framework is another tool originating out of Chris Ré’s lab and focuses on data quality/repair. This paper developed a model called AimNet in HoloClean that uses the attention mechanism to impute missing data, either discrete or continuous. Their attention-based model outperformed existing ensemble tree methods (XGBoost) or GANs on imputation of systematic missing data, as opposed to missing completely at (MCAR), across fourteen diverse benchmark datasets ranging from medical (mammography, EEG), physical (solar flare), financial, to geospatial/address data. Definitely eager to experiment with this.
Just to call out a few more that I really liked:
- Model Assertions for Monitoring and Improving ML Models : Another Software 2.0 notion about moving toward an equivalent notion of unit-tested, QA/QC’ed inference using post-hoc assertion functions.
- A System for Massively Parallel Hyperparameter Tuning: Algorithm that launches parallel grid search and successive early stopping to redistribute resources to find optimal configuration.
- Understanding the Downstream Instability of Word Embeddings: Had to do with sensitivity of embeddings under frequent retraining for NLP predictions.
- MLPerf Training Benchmark: Comprehensive ML benchmarking program.
- What is the State of Neural Network Pruning?: Review paper, self-explanatory.
There were many more great talks that I learned from, but am not going to talk about here because they were closer to the metal and I’ll just enjoy the benefits whenever they make it into PyTorch or Tensorflow.
MLOps Systems workshop
The main reason I attended was the MLOps Systems workshop, which was hosted on the third day. This workshop was focused on the ecosystem of tools for the full ML lifecycle, tracking model lineage, monitoring and drift detection, experiment tracking, CI/CD, provenance of ML artifacts, reproducibility, safe rollbacks, etc. The presentations and posters were full of best practices and guidance beyond what I can reasonably capture here.
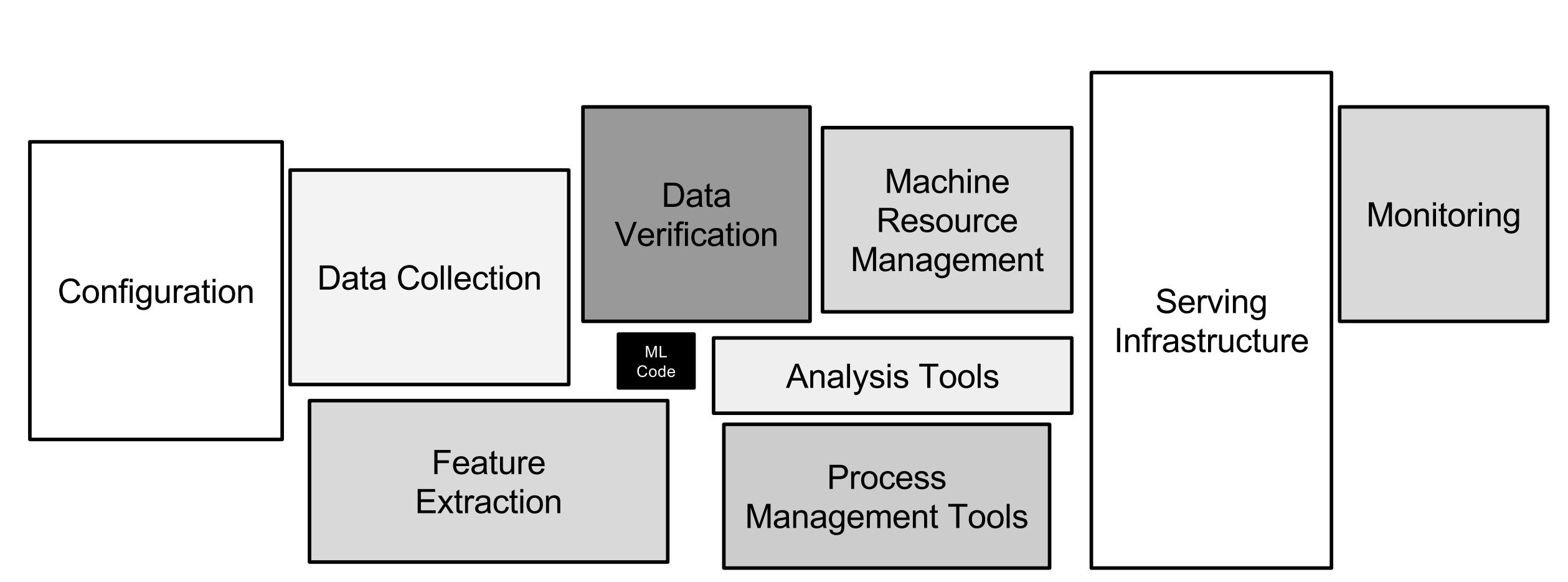
Probably two-thirds of the MLOps presentations included the following graphic from the paper Hidden Technical Debt in Machine Learning Systems (Sculley et al., NIPS 2015):
Also, I think three presentations showed a screenshot of this tweet:
The story of enterprise Machine Learning: “It took me 3 weeks to develop the model. It’s been >11 months, and it’s still not deployed.” @DineshNirmalIBM #StrataData #strataconf
— ginablaber (@ginablaber) March 7, 2018
So yeah, everybody feels the pain of getting their several hundred lines of CNN model definition into production safely.
A large philosophical focus of this workshop was that ML is a relatively a new field and it’s not always obvious how it fits into a company in terms of roles and resource allocation. If your company has machine learning engineers, data scientists, data engineers, data analysts, devops engineers, software engineers, decision scientists, statisticians, data/app product managers, etc., then who does what? Will there be an emergent “MLops engineer” title that is the corollary to the traditional devops role?
Also, what’s the ideal IDE for ML development? ML may be sufficiently different from software engineering to warrant a new approach. Should an ML model be developed in a text editor, drag-and-drop style from a GUI, just a JSON config, or other?
On the data quality front, there was another great talk by Theodoros Rekatsinas about Holoclean that dug into programmatic verification of training data via context, both at the field and tuple (set of fields) levels. See this paper for a description of the HoloClean model. The idea is to learn a probabilistic model of how clean data is generated or how errors are introduced at the tuple or cell level, then data quality operations can actually become inference queries against that model. The components of these models can be validated via integrity/domain constraints (business rule logic like zip-to-state constraints or regex validation), external datasets like curated catalogues/knowledge bases, data redundancy allowing recovery of statistical dependencies (i.e. modeling P(state|zip)), or application-aware context.
Christopher Ré gave another talk building on Snorkel which described a framework he wrote called Overton. Here is a paper describing the Overton philosophy. The name was derived from the Overton Window and was symbolic of pushing the conversation around ML systems into controversial territory. Along the lines of AutoML, the idea is to move engineers up the abstraction stack with the success metric that no engineers are writing PyTorch or TensorFlow code anymore. Overton would do data prep for training (via Snorkel), compile to TensorFlow or PyTorch and even select an appropropriate model/hyperparameters/etc., create a deployable model, and monitor model stats. Overton apparently started as a weekend hobby project, but has now served billions of queries at Apple and Google.
Ré also dropped a few controversial takes which produced not a few nodding heads in the audience: “I don’t think the people who wrote a DL model really have better insight into what it’s doing than practitioners who use them as black boxes, nor is it really even possible” was probably my favorite, but there were others. Regarding model architecture, he argued that model architecture design is easy, a tiny fraction of the lifecycle of a model with only fractional improvements possible from human effort, and that neural networks should just be designed by an architecture search over a set of coarse building blocks. He even argued that engineers shouldn’t be setting hyperparameters, as the human margin is low, optimization algorithms are basically a commodity (or should be), and you have a pretty unsophisticated algorithm if that dependent on a human. All of this should be hidden from the engineer given sufficiently smart external metric tracking.
There was a also a lot of good discussion around orchestration tools and best practices during the various talks. The discussions covered a wide range of tools from full orchestration/ML lifecycle tools like TFX and Kubeflow, to experiment tracking/versioning tools like Neptune or Weights and Biases, to other tools that (to me) seem to live on the spectrum in-between, like MLFlow. But even among the posters, there were multiple other tools or one-offs trying to mimic this type of orchestration or model tracking logic. This is a space where it seems there is no clear winner yet. None of these tools do everything and work with all frameworks, and there may yet emerge another tool to defeat them all. That said, I think my money would be on MLFlow for now from the point of view of balancing value vs. level of effort to deploy, at least for a startup (where I sit). At any rate, it’s an exciting, fast-moving space and I expect we will see a lot of awesome work coming out of these streams going forward.
Austin
This was actually my first time to Austin. It seems like a really lovely city. I had some incredible tacos and pit barbeque. Also definitely going to need an electric scooter after getting around on one for several days.